
Word Embeddings
Published: March 12, 2020Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.
A word is the most basic unit in semantic tasks that convey meaning. Since words are stored in form of strings in machines, a sequence of characters, this representation says nothing about the word meaning. Additionally, performing operations on strings is highly inefficient. So we need to map these words into some numerical form ( vectors ), in order for computers to process and understand efficiently.
To generate word representations, there are several methods but the most famous ones are Bag of Words, term frequency-inverse document frequency (TF-IDF), and word embeddings (word2vec, GloVe, fastText)
The traditional representation of words like ( BOW ) is easy to implement but you cannot infer any relationship between two words given their one-hot representation. Additionally having a high vocabulary size results in high dimension vectors which are computationally heavy to process.
Word Embedding is an efficient solution to these problems, Its main goal is to capture the contextual information in a low-dimensional vector. The underlying assumption of word embedding is that two words sharing similar contexts also share a similar meaning and consequently a similar vector representation from the model. This approach was first presented in 2003 by Bengio et al. , but gained extreme popularity with word2vec in 2013. There are also some other variants of word embeddings, like GloVe, fastext.
In this post we will be focusing on below word embeddings
word2vec
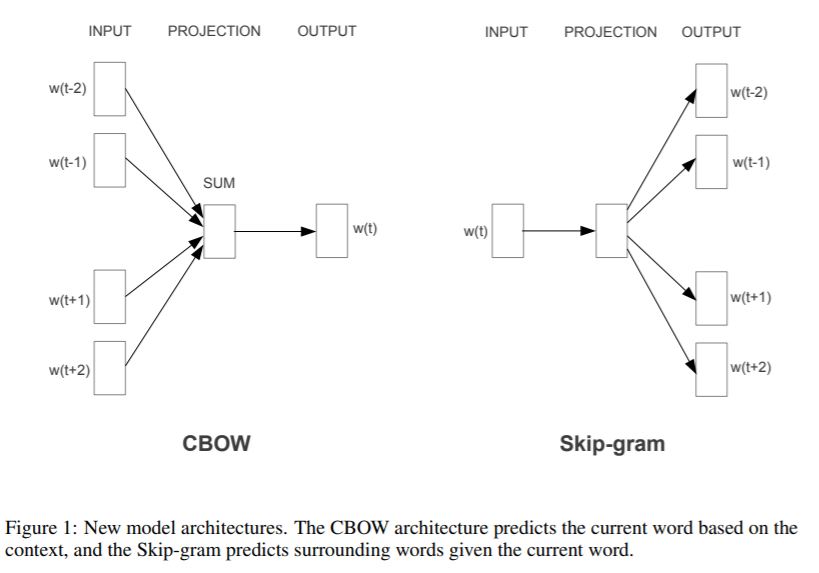
Word2vec is based on a shallow, two-layer neural network, takes a text corpus as input, and produces the word vectors as output. It first constructs a vocabulary from the training text data and then learns the vector representation of words. There are two types of Word2Vec, Skip-gram, and Continuous Bag of Words (CBOW). The underlying assumption is that the meaning of a word can be inferred by the company it keeps.
- Continuous Bag of Words (CBOW): This method takes the context of each word as the input and tries to predict the word corresponding to the context.
- Skip Gram: It’s like a flipped version of CBOW, The aim of skip-gram is to predict the context given a word.
We will implement word2vec and fastText to generate word embeddings from a corpus by making use of gensim library in python.
import numpy as np
import pandas as pd
from gensim.models import Word2Vec
from gensim.models import word2vec
import re
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
df=pd.read_csv("TWITTER_DATA.csv",nrows=60000)
df.shape
(60000, 2)
df.head()
| score | twitter_text | |
|---|---|---|
| 0 | 10 | On time |
| 1 | 0 | You cannot consider if you are a businessman w... |
| 2 | 9 | great staff |
| 3 | 8 | Good experience at reasonable cost |
| 4 | 9 | I made it safely to my destination almost on s... |
Cleaning up data before passing it through the model
ps = PorterStemmer()
replaceText="[^a-zA-Z0-9]"
def cleanupText(inp_val):
r1=re.sub(replaceText,' ',str(inp_val))
r1=r1.lower()
r1=[ps.stem(word) for word in r1.split() if word not in stopwords.words('english')]
r1=" ".join(r1)
return r1
cleanupText("I am THE greaT")
'great'
%%time
df['textCleaned']=df.twitter_text.apply(cleanupText)
Wall time: 12min 44s
df.textCleaned.tolist()[:3]
['time',
'cannot consid businessman make appoint destin chanc get time',
'great staff']
Cleaned up data in textCleaned column
df[['twitter_text','textCleaned']].head(5)
| twitter_text | textCleaned | |
|---|---|---|
| 0 | On time | time |
| 1 | You cannot consider if you are a businessman w... | cannot consid businessman make appoint destin ... |
| 2 | great staff | great staff |
| 3 | Good experience at reasonable cost | good experi reason cost |
| 4 | I made it safely to my destination almost on s... | made safe destin almost schedul |
df['textLength']=df.textCleaned.apply(lambda x : len(x.strip()))
df=df.loc[df.textLength>0,:].reset_index(drop=True)
Converting data into list of list in order to feed into gensim library, gensim expects data as a list of list
d1=[row.split() for row in df.textCleaned]
print(d1[:3])
[['time'], ['cannot', 'consid', 'businessman', 'make', 'appoint', 'destin', 'chanc', 'get', 'time'], ['great', 'staff']]
Below step builds the vocabulary, and starts training the Word2Vec model
%%time
model_w2vec = Word2Vec(d1, min_count=1,size= 50,workers=3, window =3,)
Wall time: 9.41 s
- min_count : Ignores all words with total frequency lower than this.
- size : Dimensionality of the ouput word vectors.
- window : Maximum distance between the current and predicted word within a sentence.
- workers : Use these many worker threads to train the model.
- sg : Training algorithm: 1 for skip-gram; otherwise CBOW.
Below word “love” is represented by a 50 dimensional vector
model_w2vec.wv['love']
array([-0.69568086, 0.01672682, -0.9902574 , 0.18388389, -0.99519694,
-0.85666066, -0.59419996, -0.1262948 , 0.2850825 , -1.0863582 ,
-0.65794325, 0.30300114, 0.61791545, -0.33174303, 0.74892837,
-0.11700904, 1.0420657 , 0.2157225 , 0.99739856, 0.5163384 ,
1.0602316 , 0.47526225, -0.2416768 , -0.03697897, -0.92119044,
-0.58003116, 0.03172471, -0.08266155, 0.12117439, 1.2272799 ,
0.9342238 , 0.4077084 , -0.60379475, 0.5743036 , -0.18536597,
-0.27613732, 0.20585057, -0.62984294, -1.3889954 , 1.3695644 ,
0.15080218, 1.0231798 , -0.78088504, -1.5476161 , -0.5691031 ,
-1.3392057 , 0.3351446 , 0.8769568 , 0.8490816 , 0.93095046],
dtype=float32)
model_w2vec.wv['love'].shape
(50,)
Find the top-N most similar words
model_w2vec.wv.most_similar('love')
[('amaz', 0.8949781060218811),
('pleasant', 0.8865493535995483),
('friendli', 0.8855706453323364),
('wonder', 0.87563157081604),
('polit', 0.87239670753479),
('courteou', 0.8702176809310913),
('profession', 0.8532602787017822),
('nice', 0.8532253503799438),
('fantast', 0.8528879880905151),
('great', 0.8495961427688599)]
GloVe: Global Vectors for Word Representation
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
One of the key differences between word2vec and GloVe is that word2vec is a predictive model, whereas GloVe is a count-based model.
GloVe learn their vectors by essentially doing matrix factorization on the co-occurrence counts matrix. They first construct a large matrix of (words x context) co-occurrence information, i.e. for each “word” (the rows), you count how frequently we see this word in some “context” (the columns) in a large corpus. So then they factorize this matrix to yield a lower-dimensional (word x features) matrix, where each row now yields a vector representation for each word
fastText
One major drawback of word-embedding techniques like word2vec and glove was its inability to deal with out-of-vocabulary (OOV) words. fastText is an improved version of word2vec, so instead of learning vectors for words directly, fastText represents each word as an n-gram of characters. So, for example, take the word, “love” with n=3, the fastText representation of this word is <lo,lov,ove,ve>,< and > are special symbols that are added at the start and end of each word. so instead of learning only the vector representation of word “love”, fastText would learn the vector representation for all the n-grams. The word embedding vector for “love” will be the sum of all these n-grams. This allows fastText to generate embedding vectors for words that are not even part of the training texts, using its character embeddings.
from gensim.models import FastText
%%time
model_fstext = FastText(d1, min_count=1,size= 50,workers=3, window =3,)
Wall time: 27 s
model_fstext.wv['love']
array([ 0.62340933, -0.8439905 , 0.6170727 , 0.30852202, 0.8329601 ,
0.37861598, 0.06977362, -0.48145753, -1.4531723 , 1.4516827 ,
-0.04055761, 0.05778283, 1.5469315 , -0.64948326, -1.1856103 ,
0.23647903, -0.81529766, -0.67309123, 0.80047566, -0.71018225,
1.005745 , 0.33270052, -0.6353695 , -0.9841886 , -0.2502584 ,
0.46494472, 0.31958348, 1.9747233 , -0.3298798 , 0.86469626,
-0.21526144, 1.9482663 , -0.4732637 , -0.45535222, -1.3478163 ,
-0.12220881, 0.39840353, 0.16411051, -0.47034022, 0.17784332,
0.1285966 , 0.49084577, -0.60895014, 0.86167663, -0.4114874 ,
-0.26565063, 0.08607899, 0.89927393, 0.45122787, 0.06905574],
dtype=float32)
model_fstext.wv['love'].shape
(50,)
model_fstext.wv.most_similar('love')
[('lovey', 0.9397212266921997),
('glove', 0.9353740811347961),
('llove', 0.9254188537597656),
('loveli', 0.9216791987419128),
('friendliest', 0.9210070371627808),
('loveee', 0.9198430776596069),
('friendlili', 0.9195266962051392),
('friendlli', 0.9161983132362366),
('ecofriendli', 0.9160558581352234),
('nicel', 0.9131970405578613)]
word embedding for n-grams also exist in fastText so we can handle any OOV words
model_fstext.wv['ove']
array([-0.35745192, -1.3332458 , 1.7596813 , 0.21589792, 0.7621422 ,
-0.87940675, -0.65992457, -1.0027132 , -1.2869989 , 0.72511107,
0.8236827 , -0.19925813, -0.3405544 , 0.3143684 , -0.7147689 ,
-0.08224366, -0.8158829 , -0.4053738 , 0.75310916, 0.14774014,
0.5444576 , 0.08899599, -1.7418274 , -1.5416232 , -1.0941557 ,
0.11311265, 0.05516799, 1.0099038 , 0.3634965 , 0.24894436,
-0.49282873, 1.1674355 , -1.1963383 , -0.3856887 , -1.4725461 ,
1.0493574 , 0.4661225 , -0.45622507, 0.04881619, 0.15128179,
0.31103292, 1.5720468 , -0.79352474, 0.7646491 , 0.2757908 ,
-0.03652271, -0.9542969 , -0.194845 , 0.5027483 , -0.02658518],
dtype=float32)
Conclusion
Since machine learning algorithms expect data in numerical form, traditional approaches of word representation like Bag of words (BOW) and TF-IDF have some major disadvantages, word embeddings is an efficient approach to capture the contextual information in a low-dimensional vector. Instead of retraining the model with new data, pre-trained word embedding are also available for word2vec, Glove.
References
http://veredshwartz.blogspot.com/2016/01/
https://stackabuse.com/python-for-nlp-working-with-facebook-fasttext-library/
https://cai.tools.sap/blog/glove-and-fasttext-two-popular-word-vector-models-in-nlp/
https://towardsdatascience.com/word-embedding-with-word2vec-and-fasttext-a209c1d3e12c

Leave a comment